

{kind=link}
Massive Language Fashions (LLMs) have remodeled how we work together with AI, however utilizing them sometimes requires sending your knowledge to cloud companies like OpenAI’s ChatGPT. For these involved with privateness, working in environments with restricted web entry, or just desirous to keep away from subscription prices, operating LLMs regionally is a lovely different.
With instruments like Ollama, you possibly can run giant language fashions instantly by yourself {hardware}, sustaining full management over your knowledge.
Getting Began
To observe together with this tutorial, you’ll want a pc with the next specs:
- At the very least 8GB of RAM (16GB or extra really useful for bigger fashions)
- At the very least 10GB of free disk area
- (non-obligatory, however really useful) A devoted GPU
- Home windows, macOS, or Linux as your working system
The extra highly effective your {hardware}, the higher your expertise will likely be. A devoted GPU with a minimum of 12GB of VRAM will mean you can comfortably run most LLMs. When you have the finances, you may even need to take into account a high-end GPU like a RTX 4090 or RTX 5090. Don’t fret in the event you can’t afford any of that although, Ollama will even run on a Raspberry Pi 4!
What’s Ollama?
Ollama is an open-source, light-weight framework designed to run giant language fashions in your native machine or server. It makes operating complicated AI fashions so simple as operating a single command, with out requiring deep technical data of machine studying infrastructure.
Listed here are some key options of Ollama:
- Easy command-line interface for operating fashions
- RESTful API for integrating LLMs into your purposes
- Help for fashions like Llama, Mistral, and Gemma
- Environment friendly reminiscence administration to run fashions on client {hardware}
- Cross-platform assist for Home windows, macOS, and Linux
Not like cloud-based options like ChatGPT or Claude, Ollama doesn’t require an web connection when you’ve downloaded the fashions. An enormous profit of operating LLMs regionally is not any utilization quotas or API prices to fret about. This makes it good for builders desirous to experiment with LLMs, customers involved about privateness, or anybody desirous to combine AI capabilities into offline purposes.
Downloading and Putting in Ollama
To get began with Ollama, you’ll must obtain and set up it in your system.
First off, go to the official Ollama web site at https://ollama.com/obtain and choose your working system. I’m utilizing Home windows, so I’ll be overlaying that. It’s very simple for all working techniques although, so no worries!
Relying in your OS, you’ll both see a obtain button or an set up command. In case you see the obtain button, click on it to obtain the installer.

When you’ve downloaded Ollama, set up it in your system. On Home windows, that is carried out by way of an installer. As soon as it opens, click on the Set up button and Ollama will set up routinely.

As soon as put in, Ollama will begin routinely and create a system tray icon.
![]()
After set up, Ollama runs as a background service and listens on localhost:11434 by default. That is the place the API will likely be accessible for different purposes to connect with. You possibly can verify if the service is operating accurately by opening http://localhost:11434 in your internet browser. In case you see a response, you’re good to go!

Your First Chat
Now that Ollama is put in, it’s time to obtain an LLM and begin a dialog.
Be aware: By default, Ollama fashions are saved in your C-drive on Home windows and on your private home listing on Linux and macOS. If you wish to use a special listing, you possibly can set the OLLAMA_DATA_PATH atmosphere variable to level to the specified location. That is particularly helpful you probably have restricted disk area in your drive.
To do that, use the command setx OLLAMA_DATA_PATH "path/to/your/listing" on Home windows or export OLLAMA_DATA_PATH="path/to/your/listing" on Linux and macOS.
To start out a brand new dialog utilizing Ollama, open a terminal or command immediate and run the next command:
ollama run gemma3
This begin a brand new chat session with Gemma3, a robust and environment friendly 4B parameter mannequin. Once you run this command for the primary time, Ollama will obtain the mannequin, which can take a couple of minutes relying in your web connection. You’ll see a progress indicator because the mannequin downloads As soon as it’s prepared you’ll see >>> Ship a message within the terminal:

Strive asking a easy query:
>>> What's the capital of Belgium?
The mannequin will generate a response that hopefully solutions your query. In my case, I received this response:
The capital of Belgium is **Brussels**.
It is the nation's political, financial, and cultural heart. 😊
Do you need to know something extra about Brussels?
You possibly can proceed the dialog by including extra questions or statements. To exit the chat, sort /bye or press Ctrl+D.
Congratulations! You’ve simply had your first dialog with a regionally operating LLM.
The place to Discover Extra Fashions?
Whereas Gemma 3 may work effectively for you, there are numerous different fashions accessible on the market. Some fashions are higher for coding for instance, whereas others are higher for dialog.
Official Ollama Fashions
The primary cease for Ollama fashions is the official Ollama library.

The library comprises a variety of fashions, together with chat fashions, coding fashions, and extra. The fashions get up to date nearly every day, so make certain to verify again usually.
To obtain and run any of those fashions you’re all for, verify the directions on the mannequin web page.
For instance, you may need to strive a distilled deepseek-r1 mannequin. To open the mannequin web page, click on on the mannequin title within the library.

You’ll now see the totally different sizes accessible for this mannequin (1), together with the command to run it (2) and the used parameters (3).
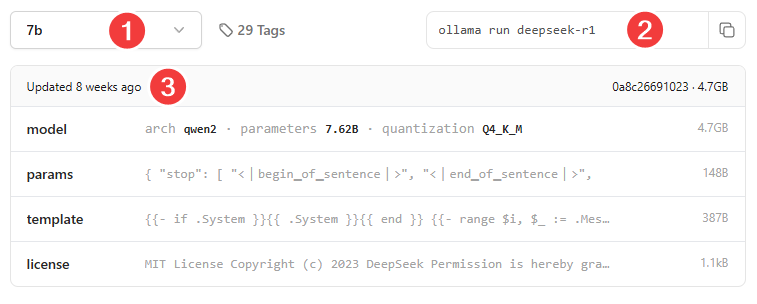
Relying in your system, you possibly can select a smaller or a smaller variant with the dropdown on the left. When you have 16GB or extra VRAM and need to experiment with a bigger mannequin, you possibly can select the 14B variant. Deciding on 14b within the dropdown will change the command subsequent to it as effectively.

Select a dimension you need to try to copy the command to your clipboard. Subsequent, paste it right into a terminal or command immediate to obtain and run the mannequin. I went with the 8b variant for this instance, so I ran the next command:
ollama run deepseek-r1:8b
Similar to with Gemma 3, you’ll see a progress indicator because the mannequin downloads. As soon as it’s prepared, you’ll see a >>> Ship a message immediate within the terminal.

To check if the mannequin works as anticipated, ask a query and it is best to get a response. I requested the identical query as earlier than:
>>> What's the capital of Belgium?
The response I received was:
<assume>
</assume>
The capital of Belgium is Brussels.
The empty <assume> tags on this case are there as a result of deepseek-r1 is a reasoning mannequin, and it didn’t must do any reasoning to reply this explicit query. Be at liberty to experiment with totally different fashions and inquiries to see what outcomes you get.